I screwed up in a major way yesterday evening. This post is part of my attempt to fix it.
| This morning I woke up to an email from a paying customer saying that they tried to print cards but couldn’t. Specifically, they said that they were able to use the Print Preview feature, but that using the actual print button, quote, “caused the server to hang.” That can’t actually happen but it was sufficiently detailed as a bug report to immediately clue me in one what probably happened: the Delayed::Job workers must be down. A quick check of the server (ps -A | grep ruby) showed that this was indeed the case. |
I quickly restarted the Delayed::Job workers then logged into the Rails console to check how many jobs had piled up. Six thousand. Oof. Most of them were low priority tasks (e.g. pinging the Mixpanel server with stats updates, which I do asynchronously to avoid having a failure there affect my users), but sixty users were affected — their print jobs were delayed. Print jobs normally take under five seconds to execute and are checked with a bit of AJAX magic which polls the server until the job is ready, which means that most of these users probably got an animated GIF spinner to look at until they got tired and closed the web page. The worst affected jobs took over twelve hours.
Happily, the downtime hit on a Saturday, which is the lightest day of the week for me. If this had happened a week ago right before Valentine’s Day over 5,000 users would have been affected.
Apologizing To Affected Users
I used the Rails console to create a list of users affected by this, and have sent individual apology emails to the 2 paying customers affected (including attachments for the cards they had tried to print). I will be contacting the trial users in a more scalable fashion. Since I don’t have permission to email free trial users (the anti-spam guarantee I give is fairly strict), I dropped the development I had planned for this morning and built a simple messaging system into the site (~20 lines of code — I love you, Rails). It gives me one-way “drop a message directly to your dashboard” functionality.
For example:
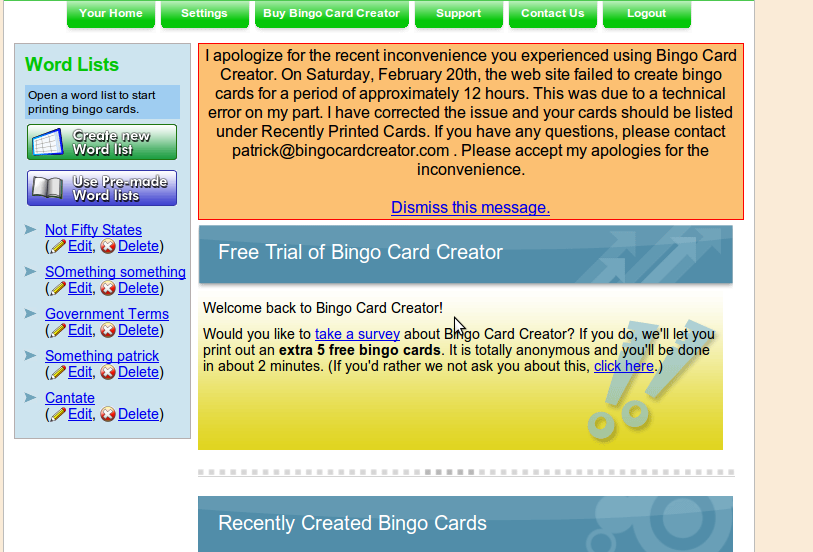
I prefer using this feature to the standard industry responses to outages:
- “Outage? What outage?”
- “Please see our status page, which we’ve conveniently located in electronic Siberia.”
- “ATTENTION ALL USERS! 0.7% of you were affected by very serious sounding things yesterday! Please be worried unnecessarily even if you weren’t affected, and swamp our support line, who we will provide no effective tools to to tell you whether you’ve been affected or not!”
It allows me to apologize directly to affected users, makes minimal demands on their attention while still almost certainly reaching them, and does not cause any issue for the other 25,000 users. Plus I can re-use this feature later in the event of needing to contact specific users without needing to email them (one obvious candidate would be plopping something straight on the screens of anonymous guests if I found something they individually needed to know, for example, if one of my automated processes caught that a recent print job of theirs did not come out right).
Preventing It From Happening Again
I’m something of a fan of Toyota’s Five Whys methodology for investigating issues like this. (It has recently been popular with the lean startup crew. My coworkers at the day job enjoyed some mostly justifiable smirks when I told them that.)
- Why couldn’t my users print? Because the Delayed::Job workers were terminated when I upgraded the production server to Ubuntu Karmic Koala last night.
- Why didn’t the post-deploy checklist catch that users couldn’t print? The post deploy checklist has “manually verify you can print cards” on it. I didn’t follow the post-deploy checklist with sufficient attention to detail because it was late (midnight) and I was tired (because I worked a six day crunch week at the day job… 30 days to go). Here, I used the Print Preview feature to verify that I could print cards (“Hey, it tests the same code path, right?”), not realizing that while it tests the same code path they have different failure scenarios if e.g. Delayed::Job workers are down. Fix: Quit day job and, regardless of how tired you are, follow the freaking checklist.
- Why weren’t you woken up by the Ride of the Valkyries playing on your cell phone when the site failed? Don’t we have a system in place to do that? It turns out that the automated diagnostic (an external service pings a URL, the URL runs various tests and throws an HTTP error if any fail, the service mails my cell phone if there is an HTTP error twice in a row) tests nginx, mongrel, the D/B, and core program logic but doesn’t test the Delayed::Job processes or sanity check the job counts. Fixed.
- Why didn’t the ‘god’ process monitor detect the workers were down? God sees every sparrow, but god only knows about the processes you tell it to manage, and my god_config.rb file has the Delayed::Job bits commented out with the notation “#This is buggy.” I don’t remember why it was buggy and my notes in SVN are similarly unhelpful. New task: unbuggy it.
- Why don’t you have commit notes, comments, or a development journal telling you what you were thinking when you found it was “buggy”? Failure to keep adequate records for “minor” changes and failure to follow up on a bug that was prioritized “Eh, get to that whenever” and then never gotten to. Fix: Look into beefing up developer documentation practices.
In the course of investigating this I discovered the update to Koala also killed Memcached on the server. (Thankfully, Memcachedb — where I persist long-term user data that for whatever reason isn’t in the database, such as A/B testing participation data — is on another server.) Unbeknownst to me, my use of memcached fails totally silently: if Rails can’t find the data in the cache it just regenerates it. That would have had very unpleasant consequences for users if it had continued until Monday, and none of my automated tests would have picked up on it, because they all ignore timing. I’ve added an explicit check to see if memcached is up and running. I’ll also look into doing something about monitoring response times.
What I Learned From Japanese Engineering
I’m indebted to my day job for teaching me both a) how to do this and b) the absolute necessity of doing it, in spite of my longtime cavalierness with software testing. It was quite a culture shock for me the first time I logged into the test server at work to deploy something and got a rap on the knuckles for not:
- Having a written explanation of exactly what commands I was going to enter.
- Having a written checklist describing what tests to perform to ensure the deploy worked, and what the expected results would be.
- Writing in the wiki that I was doing the deploy for a particular version done to close out a particular bug, so that there would be a trail to follow if the version I was about to deploy failed years from now.
That’s what we do for the test server.
All of the writing, test suites, automated test processes, and monitoring takes some time to set up and much of it generates additional overhead on all your tasks. However, in the last three years, I’ve come to recognize that it is a net time-savings over writing apology letters and doing emergency incident response, neither of which are ever fun or quick.
Alright, development journal entry over. Back to new development.
