I am a big believer in not spending time creating features until you know customers actually need them. This goes the same for OSS projects: there is no point in overly complicating things until “customers” tell you they need to be a little more complicated. (Helpfully, here some customers are actually capable of helping themselves… well, OK, it is theoretically possible at any rate.)
Some months ago, one of my “customers” for A/Bingo (my OSS Rails A/B testing library) told me that it needed to exclude bots from the counts. At the time, all of my A/B tests were behind signup screens, so essentially no bots were executing them. I considered the matter, and thought “Well, since bots aren’t intelligent enough to skew A/B test results, they’ll be distributed evenly over all the items being tested, and since A/B tests measure for difference in conversion rates rather than measuring absolute conversion rates, that should come out in the wash.” I told him that. He was less than happy about that answer, so I gave him my stock answer for folks who disagree with me on OSS design directions: it is MIT licensed, so you can fork it and code the feature yourself. If you are too busy to code it, that is fine, I am available for consulting.
This issue has come up a few times, but nobody was sufficiently motivated about it to pay my consulting fee (I love when the market gives me exactly what I want), so I put it out of my mind. However, I’ve recently been doing a spate of run-of-site A/B tests with the conversion being a purchase, and here the bots really are killers.
For example, let’s say that in the status quo I get about 2k visits a day and 5 sales, which are not atypical numbers for summer. To discriminate between that and a conversion rate 25% higher, I’d need about 56k visits, or a month of data, to hit the 95% confidence interval. Great. The only problem is that A/Bingo doesn’t record 2k visits a day. It records closer to 8k visits a day, because my site gets slammed by bots quite frequently. This decreases my measured conversion rate from .25% to .0625%. (If these numbers sound low, keep in mind that we’re in the offseason for my market, and that my site ranks for all manner of longtail search terms due to the amount of content I put out. Many of my visitors are not really prospects.)
Does This Matter?
I still think that, theoretically speaking, since bots aren’t intelligent enough to convert at different rates over the alternatives, the A/B testing confidence math works out pretty much identically. Here’s the formula for Z statistic which I use for testing:
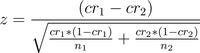
The CR stands for Conversion Rate and n stands for sample size, for the two alternatives used. If we increase the sample sizes by some constant factor X, we would expect the equation to turn into:
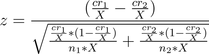
We can factor out 1/X from the numerator and bring it to the denominator (by inverting it). Yay, grade school.

Now, by the magic of high school algebra:
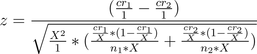
If I screw this up the math team is so disowning me:
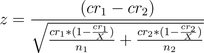
Now, if you look carefully at that, it is not the same equation as we started with. How did it change? Well, the reciprocal of the conversion rate (1 – cr) got closer to 1 than it was previously. (You can verify this by taking the limit as X approaches infinity.) Getting closer to 1 means the numerators of the denominator get bigger, which means the denominator as a whole gets modestly bigger, which means the Z score gets modestly smaller, which could possibly hurt the calculation we’re making.
So, assuming I worked my algebra right here, the intuitive answer that I have been giving people for months is wrong: bots do bork statistical significance testing, by artificially depressing z scores and thus turning statistically significant results into null results at the margin.
So what can we do about it?
The Naive Approach
You might think you can catch most bots with a simple User-Agent check. I thought that, too. As it turns out, that is catastrophically wrong, at least for the bot population that I deal with. (Note that since keyword searches would suggest that my site is in the gambling industry, I get a lot of unwanted attention from scrapers.) It barely got rid of half of the bots.
The More Robust Approach
One way we could try restricting bots is with a CAPCHA, but it is a very bad idea to force all users to prove that they are human just so that you can A/B test them. We need something that is totally automated which is difficult for bots to do.
Happily, there is an answer for that: arbitrary Javascript execution. While Googlebot (+) and a (very) few other cutting edge bots can execute Javascript, doing it on web scales is very resource intensive, and also requires substantially more skill for the bot-maker than scripting wget or your HTTP library of choice.
[+] What, you didn’t know that Googlebot could execute Javascript? You need to make more friends with technically inclined SEOs. They do partial full evaluation (i.e. executing all of the Javascript on a page, just like a human would) and partial evaluation by heuristics (i.e. grep through the code and make guesses without actually executing it). You can verify full evaluation by taking the method discussed in this blog post and tweaking it a little bit to use GETs rather than POSTs, then waiting for Googlebot to show up in your access logs for the forbidden URL. (Seeing the heuristic approach is easier — put a URL in syntactically live but logically dead code in Javascript, and watch it get crawled.)
To maximize the number of bots we catch (and hopefully restrict it to Googlebot, who almost always correctly reports its user agent), we’re going to require the agent to perform three tasks:
- Add two random numbers together. (Easy if you have JS.)
- Execute an AJAX request via Prototype or JQuery. (Loading those libraries is, hah, “fairly challenging” to do without actually evaluating them.)
- Execute a POST. (Googlebot should not POST. It will do all sorts of things for GETs, though, including guessing query parameters that will likely let it crawl more of your site. A topic for another day.)
This is fairly little code. Here is the Prototype example
var a=Math.floor(Math.random()*11);
var b=Math.floor(Math.random()*11);
var x=new Ajax.Request('/some-url', {parameters:{a: a, b: b, c: a+b}})and in JQuery:
var a=Math.floor(Math.random()*11);
var b=Math.floor(Math.random()*11);
var x=jQuery.post('/some-url', {a: a, b: b, c: a+b});Now, server side, we take the parameters a, b, and c, and we see if they form a valid triplet. If so, we conclude they are human. If not, we leave continue to assume that they’re probably a bot.
Note that I could have been a bit harsher on the maybe-bot and given them a problem which trusts them less: for example, calculate the MD5 of a value that I randomly picked and stuffed in the session, so that I could reject bots which hypothetically tried to replay previous answers, or bots hand-coded to “knock” on a=0, b=0, c=0 prior to accessing the rest of my site. However, I’m really not that picky: this isn’t to keep a dedicated adversary out, it is to distinguish the overwhelming majority of bots from humans. (Besides, nobody gains from screwing up my A/B tests, so I don’t expect there to be dedicated adversaries. This isn’t a security feature.)
You might have noticed that I assume humans can run Javascript. (My site breaks early and often without it.) While it is not specifically designed that Richard Stallman and folks running NoScript can’t influence my future development directions, I am not overwrought with grief at that coincidence.
Tying It Together
So now we can detect who can and who cannot execute Javascript, but there is one more little detail: we learn about your ability to execute Javascript potentially after you’ve started an A/B test. For example, it is quite possible (likely, in fact) that the first page you execute has an A/B test in it somewhere, and that you’ll make an AJAX call from that page you register your humanness after we have already counted (or not counted) your participation in the A/B test.
This has a really simple fix. A/Bingo already tracks which tests you’ve previously participated in, to avoid double-counting. In “discriminate against bots” mode, it tracks your participation (and conversions) but does not add them to the totals immediately unless you’ve previously proven yourself to be a human. When you’re first marked as a human, it takes a look at the tests you’ve previously participated in (prior to turning human), and scores your participation for them after the fact. Your subsequent tests will be scored immediately, because you’re now known to be human.
Folks who are interested in seeing the specifics of the ballet between the Javascript and server-side implementation can, of course, peruse the code at their leisure by git-ing it from the official site. If you couldn’t care less about implementation details but want your A/B tests to be bot-proof ASAP, see the last entry in the FAQ for how to turn this on.
Other Applications
You could potentially use this in a variety of contexts:
1) With a little work, it is a no interaction required CAPCHA for blog commenting and similar applications. Let all users, known-human and otherwise, immediately see their comments posted, but delay public posting of the comments until you have received the proof of Javascript execution from that user. (You’ll want to use slightly trickier Javascript, probably requiring state on your server as well.) Note that this will mean your site will be forever without the light of Richard Stallman’s comments.
2) Do user discrimination passively all the time. When your server hits high load, turn off “expensive” features for users who are not yet known to be human. This will stop performance issues caused by rogue bots gone wild, and also give you quite a bit of leeway at peak load, since bots are the majority of user agents. (I suppose you could block bots entirely during high load.)
3) Block bots from destructive actions, though you should be doing that anyway (by putting destructive actions behind a POST and authentication if there is any negative consequence to the destruction).
